Motivations for Virtual Memory
- ใช้ DRAM ทางกายภาพเป็นแคชสำหรับดิสก์
พื้นที่ที่อยู่ของกระบวนการสามารถเกินขนาดหน่วยความจำทางกายภาพ
ผลรวมของพื้นที่ที่อยู่ของกระบวนการหลายเกินทางกายภาพหน่วยความจำ
- จัดการหน่วยความจำลดความซับซ้อน
มีถิ่นที่อยู่หลายกระบวนการในหน่วยความจำ
*แต่ละกระบวนการที่มีอยู่ของตัวเอง
เท่านั้น "งาน" รหัสและข้อมูลที่เป็นจริงในความทรงจำ
*จัดสรรหน่วยความจำมากขึ้นในการดำเนินการตามที่จำเป็น
- Provide Protection
หนึ่งกระบวนการที่ไม่สามารถยุ่งเกี่ยวกับคนอื่น
*เพราะพวกเขาทำงานอยู่ในพื้นที่ที่แตกต่างกัน
กระบวนการผู้ใช้ไม่สามารถเข้าถึงข้อมูลได้รับการยกเว้น
*ส่วนต่าง ๆ ของช่องว่างอยู่มีสิทธิ์ที่แตกต่างกัน
Possibility of Thrashing
- เพื่อรองรับกระบวนการมากที่สุดเท่าที่เป็นไปได้เพียงไม่กี่หน้าของแต่ละขั้นตอนจะถูกเก็บไว้ในหน่วยความจำ
- แต่หน่วยความจำอาจจะเต็มเมื่อระบบปฏิบัติการนำหน้าหนึ่งในมันต้องสลับชิ้นหนึ่งออกมา
- ระบบปฏิบัติการไม่ต้องสลับออกหน้าของกระบวนการก่อนที่หน้าเป็นสิ่งจำเป็น
- ถ้ามันทำอย่างนี้บ่อยเกินไปนี้นำไปสู่thrashing:
ประมวลผลใช้เวลาส่วนใหญ่สลับหน้าเว็บของตนค่อนข้างกว่าการดำเนินการคำแนะนำของผู้ใช้
Process Execution(การดำเนินการกระบวนการ)
- ระบบปฏิบัติการที่จะนำเข้ามาในหน่วยความจำเพียงไม่กี่หน้าของโปรแกรม (รวมถึงจุดเริ่มต้นของมัน)
- รายการตารางแต่ละหน้าจะมีบิตปัจจุบัน (P บิต) ที่ถูกตั้งค่าเฉพาะในกรณีที่หน้าที่เกี่ยวข้องอยู่ในหน่วยความจำหลัก
ชุดถิ่นที่อยู่เป็นส่วนหนึ่งของกระบวนการที่อยู่ในหน่วยความจำหลักที่
- ข้อยกเว้น (ผิดหน้า) จะเพิ่มขึ้นโดย MMU เมื่ออ้างอิงหน่วยความจำที่อยู่บนหน้าไม่ได้อยู่ในหน่วยความจำหลัก (กล่าวคืออยู่ในชุด Non-resident)

- OS วางกระบวนการในสถานะที่ถูกบล็อค
แน่นอนบันทึกสถานะกับ PCB ที่สอดคล้องกัน
- ปัญหา OS ดิสก์ I / O อ่านขอให้นำเข้ามาในหน่วยความจำหลักหน้าอ้างอิงกับ
- กระบวนการก็คือการส่งไปทำงานในขณะที่ดิสก์ I / O ที่จะเกิดขึ้น
- ขัดจังหวะออกเมื่อดิสก์ I / O เสร็จสมบูรณ์
นี้ทำให้ระบบปฏิบัติการที่จะวางขั้นตอนการได้รับผลกระทบอยู่ในสถานะที่พร้อมและตารางการปรับปรุง (เช่นบิต P ในตารางหน้า)
- เมื่อกระบวนการได้รับผลกระทบมีกำหนดจะวิ่งก็รีสตาร์ทการเรียนการสอนที่ก่อให้เกิดความผิดพลาดในหน่วยความจำ
Sparse Address Space
- พื้นที่ที่อยู่เสมือนที่มีหลุมที่รู้จักกันเป็นพื้นที่ที่อยู่ห่าง
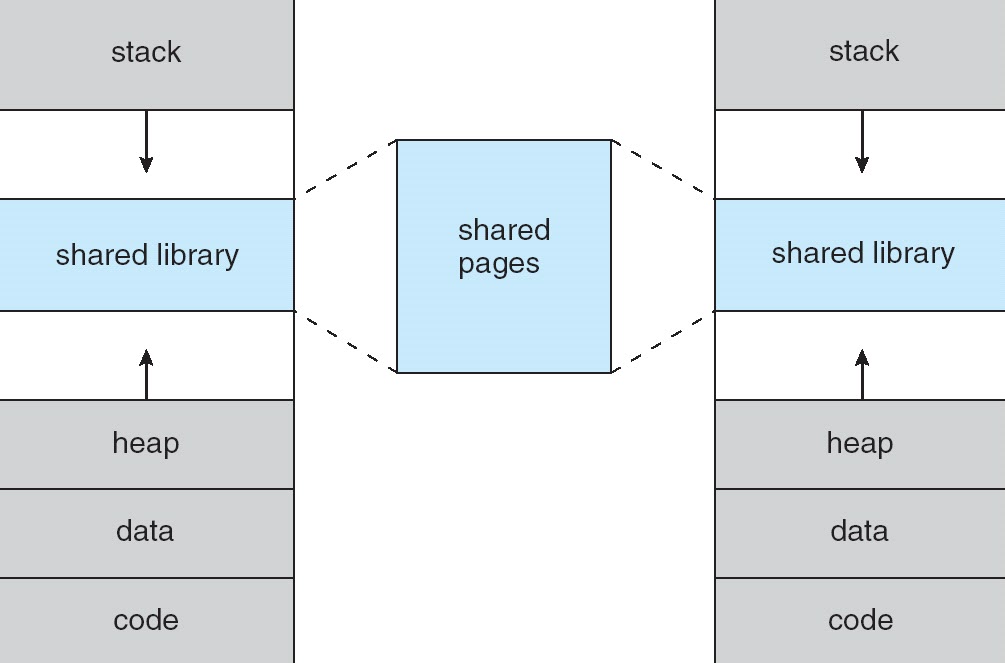
- การใช้พื้นที่ที่อยู่ห่างเป็นประโยชน์เพราะหลุมจะเต็มไปเป็นกองหรือส่วนกองเติบโตหรือถ้าเราต้องการที่จะเชื่อมโยงแบบไดนามิกห้องสมุด (หรืออาจจะเป็นวัตถุที่ใช้ร่วมกันอื่น ๆ ) ในระหว่างการทำงานของโปรแกรม



Disk (Swap Area)
Linux/x86 Process Memory Image

วิธีจัดหน่วยความจำเสมือนของLinux

- PGD:
ที่อยู่ไดเรกทอรีหน้า
- vm_prot:
การอ่าน / เขียนสิทธิ์สำหรับพื้นที่นี้
- vm_flags
ที่ใช้ร่วมกันกับคนอื่น ๆ กระบวนการหรือเอกชนที่จะ กระบวนการนี้
Linux Page Fault Handling(หน้าการจัดการความผิดพลาด)

- เป็น VA กฎหมายหรือไม่
กล่าวคือมันมีอยู่ในพื้นที่กำหนดโดย vm_area_struct?
ถ้าไม่แล้วส่งสัญญาณการแบ่งส่วนการละเมิด (เช่น.,(1)read )
- คือการดำเนินการตามกฎหมาย?
กล่าวคือสามารถกระบวนการ อ่าน / เขียนพื้นที่นี้หรือไม่?
ถ้าไม่แล้วส่งสัญญาณ การป้องกันการละเมิด (เช่น.,(2)read )
- ถ้าตกลงจัดการกับความผิด
เช่น (3)write)
Support Needed for Virtual Memory(การสนับสนุนที่จำเป็นสำหรับหน่วยความจำเสมือน)
- ฮาร์ดแวร์จัดการหน่วยความจำจะต้องสนับสนุนเพจ
- ระบบปฏิบัติการจะต้องสามารถที่จะจัดการกับการเคลื่อนไหวของหน้าระหว่างหน่วยความจำรองและหน่วยความจำหลัก
- ก่อนอื่นเราจะหารือเกี่ยวกับฮาร์ดแวร์และโครงสร้างการควบคุม; จากนั้นขั้นตอนวิธีการที่ใช้ระบบปฏิบัติการ
Paging
- โดยปกติแต่ละขั้นตอนมีตารางเพจของตัวเอง

- รายการตารางแต่ละหน้าจะมีบิตปัจจุบันpresent bit (P bit) เพื่อบ่งชี้ว่าหน้าอยู่ในหน่วยความจำหลักหรือไม่
ถ้ามันอยู่ในหน่วยความจำหลักรายการมีจำนวนเฟรมของหน้าเว็บที่เกี่ยวข้องในหน่วยความจำหลัก
ถ้ามันไม่ได้อยู่ในหน่วยความจำหลักรายการอาจมีอยู่ของหน้าเว็บที่บนดิสก์หรือหมายเลขหน้าอาจจะใช้ดัชนีตารางอื่น (มักจะอยู่ในแผ่น PCB) เพื่อให้ได้ที่อยู่ของหน้าบนดิสก์ว่า
- บิตการปรับเปลี่ยน modified bit (M bit) ระบุว่าหน้ามีการเปลี่ยนแปลงตั้งแต่มันถูกที่แล้วโหลดลงในหน่วยความจำหลัก
หากไม่มีการเปลี่ยนแปลงที่ได้รับการทำหน้าไม่ได้จะต้องมีการเขียนไปยังดิสก์เมื่อจะต้องมีการสลับออก
- บิตการควบคุมอื่น ๆ อาจจะนำเสนอการป้องกันหากมีการจัดการในระดับเพจ
อ่านอย่างเดียว / อ่านเขียนบิต
ระดับการป้องกันบิต: หน้าเคอร์เนลหรือหน้าผู้ใช้ (บิตมากขึ้นจะใช้เมื่อประมวลผลสนับสนุนมากกว่า 2 ระดับการป้องกัน)
P6 Page Table Entry

Page base address: 20 บิตที่สำคัญที่สุดของหน้าทางกายภาพ ที่อยู่ (หน้ากองกำลังจะเป็น 4 กิโลไบต์ชิด)
Avail: สามารถเขียนโปรแกรมระบบ
G: หน้าทั่วโลก (ไม่ได้ขับไล่จาก TLB งานสวิทช์)
D: สกปรก (ที่กำหนดโดย MMU ในการเขียน)
A: เข้าถึงได้ (กำหนดโดย MMU ในการอ่านและเขียน)
CD: แคชปิดการใช้งานหรือเปิดใช้งาน
WT: เขียนผ่านหรือเขียนกลับนโยบายแคชสำหรับเพจนี้
U / S: ผู้ใช้ / ผู้บังคับบัญชา
R / W: การอ่าน / เขียน
P: หน้าอยู่ในหน่วยความจำกายภาพ (1) หรือไม่ (0)
TLB and Virtual Memory
- ป.ร. ให้ไว้เป็นที่อยู่ตรรกะประมวลผลตรวจสอบแบบ TLB
- ถ้ารายการตารางเพจที่เป็นปัจจุบัน (ตี) จำนวนเฟรมถูกดึง และจริง (ทางกายภาพ) ที่อยู่จะเกิดขึ้น
- ถ้ารายการตารางหน้าจะไม่พบใน TLB (พลาด) หน้าจำนวนที่ใช้ในการดัชนีตารางหน้ากระบวนการ
ถ้าบิตในปัจจุบันมีการตั้งค่าแล้วกรอบที่สอดคล้องกันมีการเข้าถึง
ถ้าไม่ผิดหน้าออกเพื่อนำมาในหน้าอ้างอิงในหน่วยความจำหลัก
- TLB มีการปรับปรุงเพื่อรวมรายการหน้าใหม่

Page Tables and Virtual Memory(ตารางหน้าและหน่วยความจำเสมือน)
- ระบบคอมพิวเตอร์ส่วนใหญ่สนับสนุนพื้นที่ที่อยู่เสมือนมีขนาดใหญ่มาก
32-64 บิตจะใช้สำหรับที่อยู่ตรรกะ
ถ้า (เท่านั้น) 32 บิตจะถูกนำมาใช้กับหน้า 4KB โต๊ะหน้าอาจจะมี 220 รายการ
- ตารางหน้าทั้งหมดอาจใช้เวลาถึงหน่วยความจำมากเกินไป ดังนั้นตารางหน้ามักจะเก็บไว้ในหน่วยความจำเสมือนและยัดเยียดให้เพจ
เมื่อกระบวนการที่กำลังทำงานเป็นส่วนหนึ่งของตารางเพจของมันจะต้องอยู่ในหน่วยความจำหลัก (รวมถึงรายการตารางหน้าของหน้าการดำเนินงานในขณะนี้)
จะเกิดอะไรขึ้นถ้ามันไม่ได้อยู่ในหน่วยความจำหลัก?

Page tablesอื่นๆที่ไม่ใช่ไดเรกทอรีจะสลับเข้าและออกตามความจำเป็น
OS Policies for Virtual Memory(นโยบายของOS สำหรับหน่วยความจำเสมือน)

Replacement policy (นโยบายเปลี่ยน): เป็นที่หนึ่งที่จะสลับออกเมื่อไม่มีกรอบที่ไม่ได้ใช้?
Resident set management (การจัดการชุดถิ่นที่อยู่): กระบวนการ C มักจะมี 2 เฟรม?
Cleaning policy(นโยบายการทำความสะอาด): 0 หน้าในแรมจะแตกต่างจากภาพในพื้นที่แลกเปลี่ยน เมื่อการปรับปรุง?
Fetch policy (Fetch นโยบาย):เมื่อ OS เรียก 2 หน้าก็ควรเรียกหน้าอื่น ๆ ใกล้?
Fetch Policy
- กำหนดเมื่อหน้าควรจะนำเข้ามาในหน่วยความจำหลัก สองนโยบายที่เหมือนกัน:
เพจความต้องการเพียง แต่นำหน้าในหน่วยความจำหลักเมื่อมีการอ้างอิงที่ทำไปยังสถานที่บนหน้าเว็บ (เช่นเพจตามความต้องการเท่านั้น)
*ผิดหน้าหลายคนเมื่อขั้นตอนการเริ่มต้นครั้งแรก แต่ควรลดลงเป็นหน้ามากขึ้นจะนำเข้ามาใน
- Prepaging นำในหน้าเกินความจำเป็น
มันมีประสิทธิภาพมากขึ้นเพื่อนำมาในหน้าเว็บที่อยู่ติดกันบนดิสก์
ประสิทธิภาพไม่เป็นที่ยอมรับแน่นอน: หน้าพิเศษนำเข้ามาคือ "มักจะ" ไม่ได้อ้างถึง
Placement policy(นโยบายการจัดตำแหน่ง)
- ที่กำหนดในหน่วยความจำที่แท้จริงหน้ากระบวนการอยู่
- ที่ไหนที่จะวางหน้าไม่เกี่ยวข้องตั้งแต่เฟรมหน่วยความจำทั้งหมดจะเทียบเท่า (ไม่เป็นปัญหา)
Replacement Policy(นโยบายเปลี่ยน)
- ข้อเสนอกับการเลือกของหน้าในหน่วยความจำจะถูกแทนที่เมื่อหน้าใหม่จะมาใน
- นี้เกิดขึ้นเมื่อใดก็ตามที่หน่วยความจำเต็ม (ไม่มีกรอบฟรีที่มีอยู่)
- เกิดขึ้นบ่อยครั้งตั้งแต่ OS พยายามที่จะนำเข้ามาในกระบวนการหน่วยความจำให้มากที่สุดเท่าที่จะสามารถเพิ่มระดับ multiprogramming
- ไม่ทุกหน้าในหน่วยความจำที่สามารถเลือกเพื่อทดแทน
- เฟรมบางส่วนจะถูกล็อค (ไม่สามารถเพจหมด):
มากของเมล็ดจะจัดขึ้นในเฟรมล็อคเช่นเดียวกับโครงสร้างการควบคุมที่สำคัญและ I / O บัฟเฟอร์
- ระบบปฏิบัติการอาจตัดสินใจว่าชุดของหน้าการพิจารณาให้เปลี่ยนควรจะ:
จำกัด เหล่านั้นของกระบวนการที่ได้รับความเดือดร้อนความผิดหน้า
ชุดของทุกหน้าในกรอบปลดล็อค
- การตัดสินใจสำหรับการตั้งค่าของหน้าเว็บที่จะได้รับการพิจารณาสำหรับการทดแทนที่เกี่ยวข้องกับresident set management strategy:
วิธีเฟรมหน้าจำนวนมากกำลังจะจัดสรรให้แต่ละขั้นตอน? เราจะพูดถึงเรื่องนี้ในภายหลัง
- ไม่ว่าสิ่งที่เป็นชุดของหน้าการพิจารณาการเปลี่ยนข้อเสนอreplacement policy(นโยบายการเปลี่ยน)กับขั้นตอนวิธีที่จะเลือกหน้าภายในชุดที่
- ต้องการขั้นตอนวิธีการที่ก่อให้เกิดอัตราต่ำสุดหน้าผิด
- ประเมินโดยขั้นตอนวิธีการทำงานบนสตริงโดยเฉพาะอย่างยิ่งของการอ้างอิงหน่วยความจำ (สตริงอ้างอิง) หรือคำสั่งอ้างอิงหน้าและการคำนวณจำนวนผิดหน้าและเปลี่ยนหน้าในสตริงที่
- ในตัวอย่างทั้งหมด
ขนาดชุดที่มีถิ่นที่อยู่ (เช่นจำนวนเฟรม) คือ 3
- โดยทั่วไปเป็นตัวเลขของการเพิ่มขึ้นของเฟรมจำนวนหน้าหยดความผิดพลาด
Note on Counting Page Faults(หมายเหตุนับผิดหน้า)
- เมื่อหน่วยความจำที่ว่างเปล่าในแต่ละหน้าใหม่ที่เรานำมาเป็นผลมาจากความผิดพลาดหน้า
- เพื่อประโยชน์ในการเปรียบเทียบขั้นตอนวิธีการที่แตกต่างกันเราจะไม่นับความผิดพลาดเหล่านี้เริ่มต้นหน้า
เพราะจำนวนเหล่านี้จะเหมือนกันสำหรับขั้นตอนวิธีการทั้งหมด
- แต่ในทางตรงกันข้ามกับสิ่งที่จะปรากฏในตัวเลขเหล่านี้อ้างอิงเริ่มต้นจริงๆการผลิตผิดหน้า
Replacement Policy
- เราจะศึกษานโยบายการเปลี่ยนสี่:
ที่เหมาะสม
LRU (ใช้น้อยที่สุดเมื่อเร็ว ๆ นี้)
FIFO (ครั้งแรกในครั้งแรกออก)
นาฬิกา
Comparison
| Performance | to implement | |
| Optimal | Optimal | Impossible |
| LRU | Near optimal | Expensive |
| FIFO | Not good | Simple |
| Clock | Good | OK |
The Optimal Policy(นโยบายที่เหมาะสม)
- แทนที่เพจที่เวลาในการอ้างอิงต่อไปเป็นที่ยาวที่สุด
- ผลลัพธ์ในจำนวนน้อยที่สุดของผิดหน้า
- เป็นไปไม่ได้ที่จะใช้ (จำเป็นต้องรู้อนาคต) แต่ทำหน้าที่เป็นมาตรฐานในการเปรียบเทียบกับขั้นตอนวิธีการอื่น ๆ
The LRU Policy
- แทนที่หน้าเว็บที่ยังไม่ได้รับการอ้างอิงเวลาที่ยาวที่สุด
ตามหลักการของถิ่นนี้ควรจะเป็นหน้าอย่างน้อยน่าจะถูกอ้างถึงในอนาคตอันใกล้
ดำเนินการเกือบทั้งเป็นนโยบายที่ดีที่สุด
ตัวอย่าง: กระบวนการของ5หน้าเว็บที่มีระบบปฏิบัติการที่แก้ไขขนาดชุดที่resident set size to 3

Implementation of the LRU Policy(การดำเนินการตามนโยบายอาร์)
- หน้าแต่ละคนจะได้รับการติดแท็ก (ในรายการตารางเพจ) ที่มีเวลาในแต่ละอ้างอิงหน่วยความจำ
- หน้าอาร์เป็นหนึ่งที่มีค่าของเวลาที่เล็กที่สุด (ความต้องการที่จะค้นหาความผิดแต่ละหน้า)
- นี้จะต้องใช้ฮาร์ดแวร์ราคาแพงและการจัดการที่ดีของค่าใช้จ่าย (เช่นการปรับปรุงตาราง)
- น้อยมากดังนั้นระบบคอมพิวเตอร์ที่ให้การสนับสนุนฮาร์ดแวร์เพียงพอสำหรับนโยบายการเปลี่ยนอาร์จริง
- ขั้นตอนวิธีการอื่น ๆ จะถูกนำมาใช้แทน
The FIFO Policy (นโยบาย FIFO)
- แทนที่หน้าเว็บที่ได้รับในหน่วยความจำที่ยาวที่สุด
- ง่ายที่จะใช้
ขนมกรอบหน้าจัดสรรให้กระบวนการเป็นกันชนกลม (เช่นรายการกลม)
*เมื่อบัฟเฟอร์เต็มหน้าที่เก่าแก่ที่สุดจะถูกแทนที่
ดังนั้นต้องมีเพียงตัวชี้ว่าวงการผ่านกรอบหน้าของกระบวนการ
ผลงานที่ดีไม่ - หน้าแทนที่อาจมีความจำเป็นอีกครั้งเร็ว ๆ นี้
- หน้าใช้บ่อยมักจะเป็นที่เก่าแก่ที่สุดดังนั้นมันจะเป็น
ซ้ำแล้วซ้ำอีกเพจโดย FIFO